
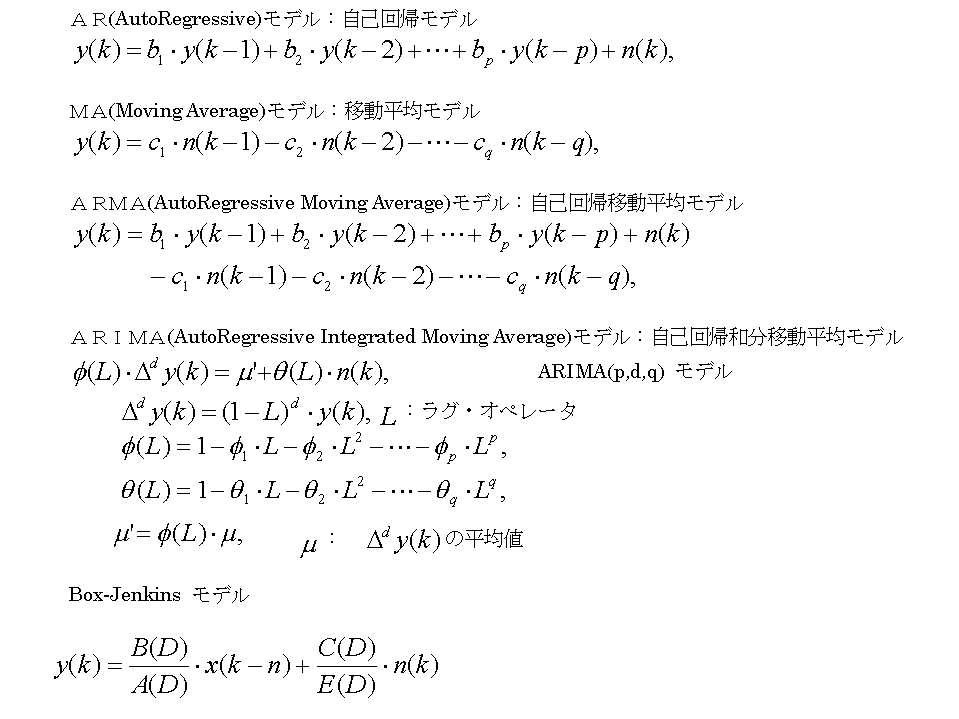
我々は、将来を予測して行動することが多い。現在や将来の社会で必要となるであろう能力を想定して、学生諸君も大学、学科、受講科目等を選択していると思う。この予測に使われる技術は、システム制御技術のモデリングやシステムのパラメタータ同定、状態推定(あるいは、観測)と言われる技術と類似ものである。予測は予想とは異なり、数理科学の応用で将来値を合理的に求めるものである。予測技術が使われる例としては、GNP、外国為替、株価、物価、経済成長率等の経済予測、電力、水、商品や製品、サービス等の需要予測、天候や気温の気象予測等が良く知られている。
予測技術といっても、対象とする分野によって大きく内容が異なると考えられる。例えば、航空宇宙の分野における人工衛星やロケットの将来の位置は、力学の法則に基づいて計算すると、正しい位置が予測できる。この場合の予測モデルとは、運動の法則のことであり、モデルのパラメータや外力は、人工衛星やロケットの質量、地球や他の衛星や恒星からの引力である。一方、経済現象の株価等の予測を行う時のモデルは、運動の法則のようなものは存在しないので、計測されたデータ等から造るのが一般的である。すなわち、追試によっても同じ法則に従う物理や化学の現象ではなく、経営工学が扱うような経済や人間の意志を反映するようなシステムの予測は、かなり困難な要素を含んでいる。
予測技術には、分野別の知識を活用するものと過去の時系列データを利用するものとがある。例えば、株価予測の場合には、前者をファンダメンタル分析による予測といい、後者をテクニカル分析による予測と呼ばれる。実際的には、両方の良いとこ取りができるシステムの開発が求められている。ここでは、ビジネス予測について考える。また、カルマンフィルタのような確率的取り扱いを必要とする予測は取り扱わず、指数平滑や自己回帰のようなモデルで予測する技術について紹介する。
1. 予測モデル
過去の実績データを説明する、あるいは、過去の実績データにフィットする数式モデルを求め(モデリング)、この数式モデルを用いて将来値を予測することが多い。この数式モデルとしては、様々なものが考えられている。以下に、代表的なモデルを紹介する。
記号の説明: Fk
は、時刻kにおける、Xkの予測値
Xk は、時刻kにおける実現値
D は、一時刻遅れを表わすオペレータ、よって、Xk =D・Xk-1
L は、L時刻遅れを表わすオペレータ、よって、Xk =L・Xk-L
α、β、γ、a, b, c, 等はモデルの係数
である。
2. モデルの評価方法
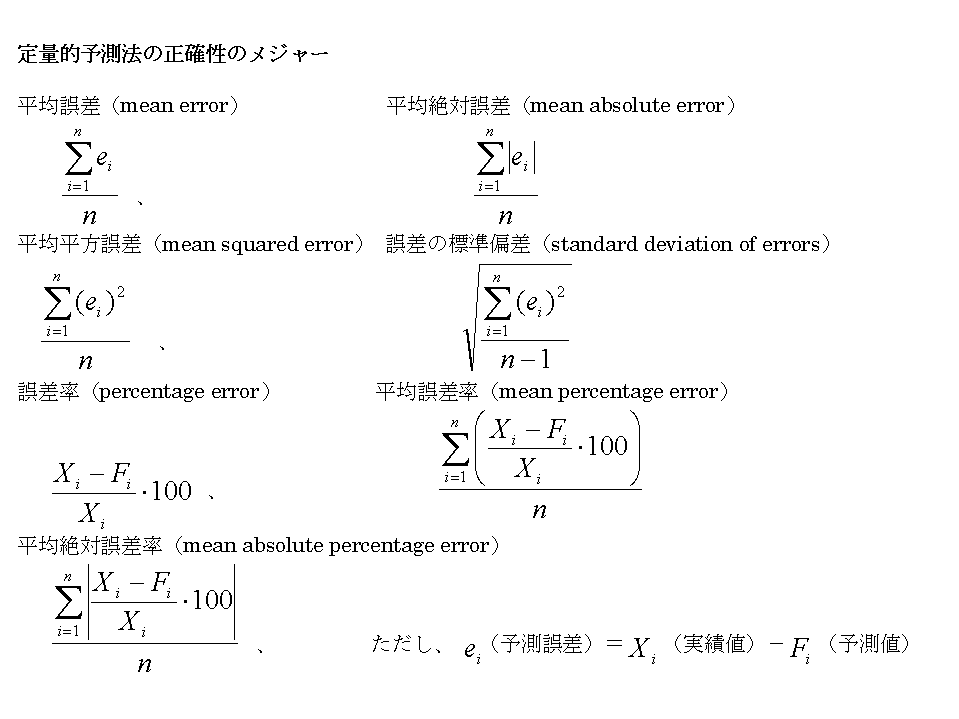
予測の善し悪しを評価する基準はいくつか考えられている。基本的には、精度良い予測をすることが最終目標ではないので、予測結果を見ながらビジネスの意思決定をする人にとって、有益な情報となることが望ましい。すなわち、意思決定者にとって、分かり易く、使いやすい評価基準を選択する必要がある。以下に、代表的な評価基準のいくつかを紹介する。
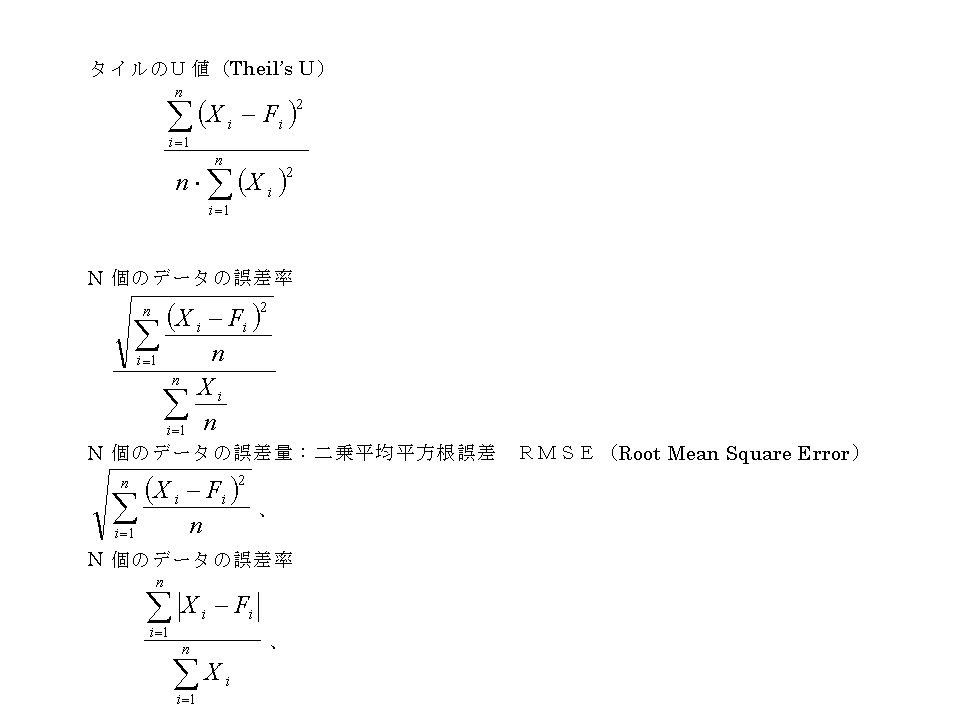
モデルのパラメータ数と予測精度のトレード・オフを考慮した評価法
AIC( Akaike’s Information Criterion: 赤池の情報量基準)= - loge(最大尤度) + 2×(予測モデルのパラメータ数)
FPE( Final Prediction Error:最終予測誤差)規範=(n−1)/(n−p−1) σ2^(p)
ただし、 p :予測モデルのパラメータ数、n: データ数、 σ2^:予測誤差分散の推定値
モデルのあてはまりの度合いとモデルに含まれる未知パラメ ータ数を考慮にいれた規準で、AIC の値、あるいは、FPEの値が最小となる予測モデル を選択する
3. 例題
4. 予測技術実用への課題
1、データの洗浄
計測されたデータ Xk を目的に合わせて前処理をする必要がある。例えば、月当たりの商品の販売量を予測する場合には、過去の月次の販売量データは、異なる日数(28日、29日、30日、31日のいづれか)に基づいたデータとなっているので、日数を合わせたデータに調整した修正データを元に予測モデルを造る必要がある。さらに、販売店の店舗数が店舗展開により異なっている時期のデータを含む場合などは、店舗を合わせたデータに修正する必要がある。等
2、過去実績にフィッティングする予測モデルと説明変数による予測モデル(あるいは、人間のもつ関連知識)の融合活用方法
関連用語の説明
アンサンブル学習( Enssemble
Learning ) : ある一つの予測問題に対し、複数の学習機械の予測結果を結合して、より精度の高い予測値を得るための学習手法の枠組みのこと。